





Nebyla by dnes technologická akce, aby na ní nepadlo slovo o umělé inteligenci. Podobně tomu bylo i na konferenci Media a Technologie, která se konala v Pardubicích v polovině října. Nebylo to však pouhé teoretizování, ale i příklady praktického použití. A dokonce s výzvou, aby se posluchači sami zapojili do vytváření jednoduchých řešení. V dnešním článku najdete i podrobnější návod, jak s AI můžete pracovat už teď.
V prvním bloku konference, který se zabýval převážně legislativou, bylo vidět, jak technologie předbíhají legislativu, neboť o Nařízení EU o harmonizovaných pravidlech pro umělou inteligenci (AI ACT) se tam nemluvilo, byť je Nařízení již platné a některá jeho ustanovení budou použitelná již od února příštího roku. Do celé problematiky se rovnou vstoupilo praktickým popisem několika užitečných aplikací umělé inteligence AI při zpracování audio/video obsahu.
I když jsou České Radiokomunikace (CRA) veřejnosti známé jako podnik provozující infrastrukturu pro televizní a rozhlasové vysílání, uniklo možná všeobecné pozornosti, že již přes 10 let provozují také služby online streamování a další služby pro velké mediální domy. S přednáškou na konferenci vystoupil Robert Mitka, vedoucí OTT služeb CRA a v úvodu řekl: „V Českých Radiokomunikacích jsme začali budovat naši infrastrukturu a postupně přidávali další služby. Jako přidanou hodnotu pro naše zákazníky, kterým doručujeme video obsah, doplnění o službu zpracování video obsahu.“
Umělá inteligence AI se najednou neobjevila. Je tu s námi již desítky let, což na konferenci Media a Technologie v úvodu své přednášky potvrdil Robert Mitka, který umělou inteligenci na Matematicko-fyzikální fakultě vystudoval již před 30 lety. Tehdy však netušil, že se k ní někdy dostane a v současnosti ji může aplikovat v praxi.

Robert Mitka na konferenci Media a Technologie (Foto: Václav Udatný)
Ještě před tím, než uvedeme několik příkladů využití AI pro zpracování vizuálního obsahu, popišme si její vývoj.
AI (Artficial Intelligence – umělá inteligence). Co je a jak se vyvíjela
Umělá inteligence (AI) je technologie, která napodobuje lidskou inteligenci k provádění různých činností. Využívá strojové učení (ML=Machine learning), hluboké učení (DL= Deep Learnig) a neuronové sítě k dosažení požadovaného cíle. Zjednodušeně řečeno, odkazuje na schopnost strojů nebo počítačových systémů provádět úkoly, které obvykle vyžadují lidskou inteligenci.
Je to obor studia a technologie, jehož cílem je vytvořit stroje, které se mohou učit ze zkušeností, přizpůsobovat se novým informacím a provádět úkoly bez explicitního programování. Umělá inteligence (AI) označuje simulaci lidské inteligence ve strojích, které jsou naprogramovány tak, aby myslely jako lidé a napodobovaly jejich činy.
Za prvopočátek je možno považovat rok 1986, kdy vyšla v rámci supiny PDP (Parallel Distributed Processing) na M.I.T (Massachusetts Institute of Technology) práce o „Učení reprezentací zpětným šířením chyb“, následované roku 1995 konvolučními neuronovými sítěmi (CNN) hlubokého učení.
Další vývoj v roce 2014 postoupil k dnešní generativní AI – GAN (Generative Adversial Network) sítím, které generují obsah pomocí generátorové neuronové sítě, která je testována proti druhé neuronové síti: diskriminátoru, který určuje, zda obsah vypadá “reálně”. Základní ideou je nepřímé trénování a jsou základem generování obrázků.
Na základě architektury tzv. transformerů v roce 2017, vyvinula společnost Open AI typ velkého jazykového modelu GPT (Generative Pre-trained Transformer), který je dnes pokročilým modelem umělé inteligence a schopný vygenerovat text na základě zadaných informací. Nejnovější verze Chat GPT 5 má být uvolněna koncem tohoto roku, nebo začátkem příštího. Jeho hlavní předností má být možnost zpracovat rychle až dvojnásobek slov ve srovnání s dnešní poslední verzí GPT-4o.
Generativní AI
Neuronové sítě generativní AI využívají natrénované modely pro vytvoření nového obsahu z již existujících dat jako jsou text, audio, video, obrázky a programovací kód, na základě vzorů a příkladů ze stávajících dat. Zahrnuje trénovací algoritmy pro pochopení a analýzu velké datové sady a následné použití těchto znalostí k vytvoření nového, originálního obsahu podobného stylu nebo struktuře jako trénovací data.
K vytvoření nového obsahu neexistuje jediný postup. Podle cílového zaměření jsou použity různé techniky a jejich varianty pro vytvoření generativních modelů. Tyto modely jsou trénovány na masivních souborech dat, aby porozuměly vzorcům a základním strukturám. Modely se učí vytvářet nové instance, které zrcadlí trénovací data tím, že zachycují statistické rozložení vstupních dat během trénovací fáze.
Na vytváření textů tak není ChatGPT jediným modelem, existují i další jako LLAMA nebo BERT vytvořený Googlem. Pro vytváření obrázků a videí jsou to: DALL-E, Midjourney nebo Stable Diffusion, pro generování hudby jsou to například modely Jukebox nebo Stable audio.
Dnešní doba je typická tím, že do všeobecného podvědomí veřejnosti se v souvislosti s AI dostaly velké jazykové modely typu GPT, které jsou vlastně vrcholem letitého snažení v této oblasti. ChatGPT není jen technický úspěch, ale skok v použitelnosti, přístupnosti a uživatelské zkušenosti. Ukázalo se, že žádný jiný nástroj již není jen funkcí zabudovanou do větších softwarových produktů, ale celým průmyslem, který začal ovládat trh.
AI pro zpracování audio/video obsahu a náměty na vlastní odzkoušení
Právě přednáška Roberta Mitky se zaměřila na nástroje umělé inteligence, které tady byly před 10 lety, jako daleko menší a skromnější modely inteligence a které dokázaly zpracovat obsah efektivněji a s menším nárokem na výpočetní výkon. Přednášející představil pár námětů, které „…si můžete sami vyzkoušet, pokud máte trochu technologického ducha a umíte si stáhnout nějaké vývojové prostředí. Jsou to nástroje, které jsou volně k dispozici a můžete si s tím pohrát, samozřejmě to vyžaduje mít technologického ducha“.
Vyšší rozlišení pomocí AI
Typickým příkladem je použití ESPCN (Efficient Sub-Pixel Convolutional Neural Network) pro upkonverzi videa na displejích z nižšího SD rozlišení na vyšší (HD/UHD). To používají léta výrobci televizorů, jak jsme popsali v článku „Televizory v roce 2003. Umělá inteligence vládne skoro všem“.
Použitá neuronová síť pro tuto aplikaci byla inspirována tím, jak funguje naše lidské oko, které se dívá ne na jednotlivé pixely, ale snaží se abstrahovat a hledat v obrazu celé objekty. Konvoluční sítě jsou vhodné právě po zpracování obrazových materiálů a dají se využít i na různé jiné případy.
Udělejte si sami z černobílých barevné filmy a fotky
Dalším takovým příkladem, kde lze využít konvoluční síť, je obarvování video obsahu a je to poměrně přímočaré použití. Při učení neuronové sítě je nutné vlastně učit barvy podle toho, do jakého období spadá video kontent. Pokud by se síť učila na barevné obrázky z dnešní doby, tak ten výsledný audiovizuální záznam by se obarvil dnešními barvami. Takže pokud trénujete a chcete obarvit film, třeba jako je ukázka z roku 1922 z civilní války, tak je zapotřebí trénovat na barevných obrázcích té doby, aby se dosáhlo odpovídající barevnosti. Podívejte se na výsledek v 15sekundovém videu z filmu z roku 1922:
Pomocí použitého nástroje DeOldify, který je možno najít na internetu přímo i s knihovnu, je možno si zkusit obarvení i třeba staré černobílé fotky babiček, či prarodičů. K tomu stačí navštívit volně přístupný Colab notebook a spustit si video návod na youtube.
Detekce tváří
Další oblastí, kterou v CRA Mitkova skupina zkoumala, byla detekce tváří v obraze. K tomu slouží nástroj „Face Detector“ MTCNN (Multitask cascaded CNN). Při tom je třeba vzít v úvahu různé velikosti obličejů, případně velikosti tváře omezit v případě, že se má hledat v nějaké davové scéně nebo publiku, aby nedošlo k falešné identifikaci.
Titulkování
Dnešní doba velkých jazykových modelů (LLM) v technologické rovině jsou transformery, které zpracovávají jak text, tak i audiovizuální obsah. První pokusy s automatickým titulkováním začaly již před léty, ale jejich chybovost byla vysoká, ale s příchodem transformerů – které jsou součástí GPT – se chybovost titulkovacích nástrojů zlepšila, jak věda pokročila. Na konferenci byl prezentován obrázek vytvořený nástrojem Whisper od společnosti OpenAI, který je k dispozici od loňského roku.
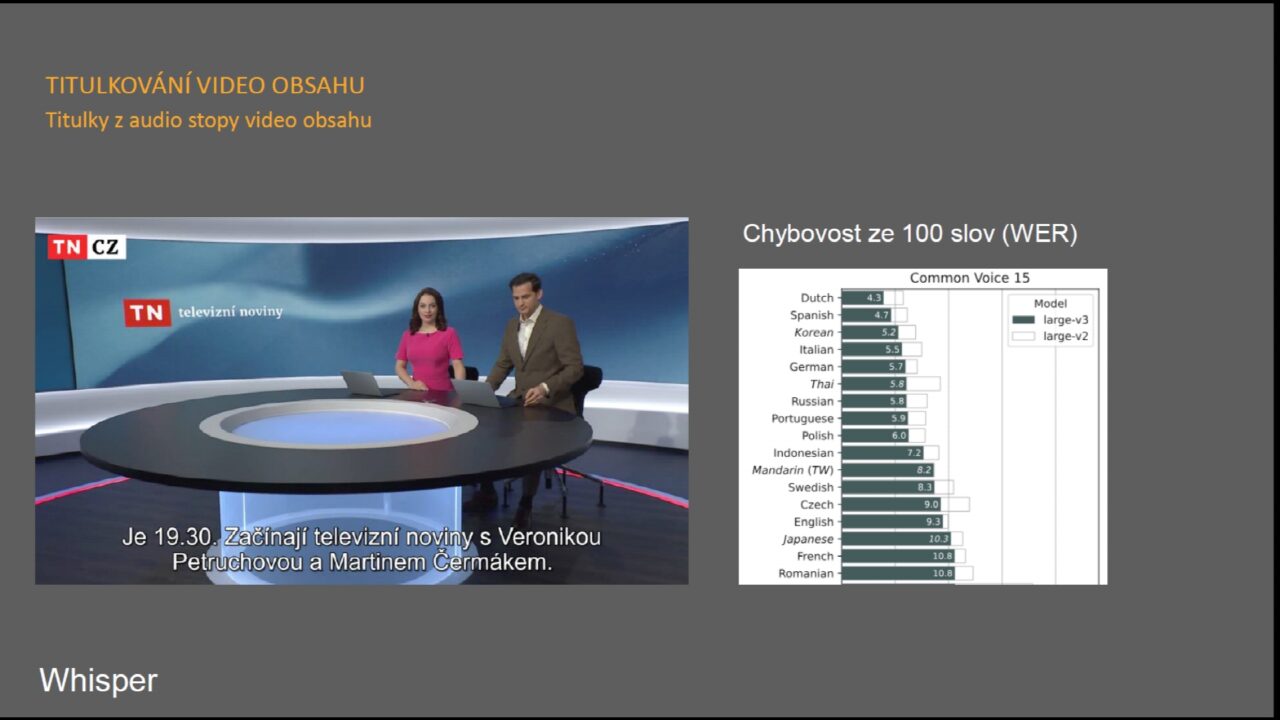
Na pravé straně je porovnání dvou modelů titulkování: verze tři a verze dva (Zdroj: prezentace R.Mitka, konference Media a Technologie, 2024)
Na obrázku je vidět chybovost různých verzí jednoho modelu, která se měří na počet chyb ve 100 slovech. Modely se totiž stále zlepšují a Whisper, jako jeden z mála modelů, umí zpracovat i slovanské jazyky včetně češtiny. To není úplně přirozené, protože český jazyk, je hodně zanedbáván. Na poli AI tomu vládne angličtina a čeština není úplně nachystaná.
Chybovost 9 % znamená zhruba devět chyb ve 100 slovech, což jsou většinou často nějaká interpunkční znaménka, ale občas úplně nějaké překlepy slov nebo nějaká špatně interpretovaná slova.
Překlady titulků z/do jiných jazyků
Když už máte titulky, tak je možné přidat k tomu další model, a to je automatický překlad. Pokud dostanete z agenturního zpravodajství Reuters nebo jiných agenturních zpráv anglický materiál a je potřeba jej rychle přepsat do češtiny, tak můžete využít překladatelský nástroj DeepL, který je výborný pro překlad jednotlivých slov, avšak skutečně titulky, které vytvoříte z anglických, jsou jen skvělým podkladem pro přepsání do češtiny. Není možné se totiž spoléhat na to, že vám to AI všechno dokonale udělá. V tom stavu to zatím není a asi dlouho nebude. Titulky se musí zpracovat ve více krocích, po prvním překladu, textovém podkladu, musí v dalším kroku dojít k editaci a k úpravě svázaných časových značek pro synchronizaci s obrazem, i vzhledem k vyhraženému místu a počtu řádků, které titulky ve videu mají. Nelze to hned publikovat, ale ještě stále to musí projít lidskou kontrolou.
Rozpoznávání mluvčích i pro nedoslýchavé
Co se dá dále dělat s titulky? Pokud máte vytvořené titulky, tak ještě dokážete i rozpoznat, kdo a kdy mluví, a podle toho titulky obarvit. Tuto aplikaci OpenAI Whisper+ pyannote.audio aktuálně připravuje CRA pro jeden mediální dům, protože asociace neslyšících požaduje tuto funkcionalitu proto, aby neslyšící diváci rozpoznali, kdo mluví, zda mluví žena nebo muž. Oni odstín hlasu nemají možnost slyšet, tak jim obarvení titulků, na příklad žena zeleně/muž červeně, nahradí odstín hlasu.
Rozpoznávání ruchů a popis scény video obsahu
K tomu slouží síť CLAP (Large Scale Constrastive Language-Audio Pretraining), která dokáže správně určit zvuk zavírajících dveří na 98 %, což v případě titulků pro neslyšící je možno automaticky doplňovat. Je však nutno nejdříve celou situaci zmapovat, případně očistit zvuky, které do filmu nepatří, a nadefinovat ty, které by se měly identifikovat.
Aplikace, založené na velkých jazykových modelech (LLM) nemusí mít jenom na vstupu obrázky nebo text, ale dokážou zpracovat už celé video. V tomto případě zatím jsou to jenom 1520vteřinové videa, ukázky, ale umělá inteligence, neuronová síť v tomto případě Llava-Next dokáže vlastně popsat, co se v tom videu odehrává.

Příklad použití nástroje AI pro popis obrazové scény (Zdroj: : prezentace R.Mitka, konference Media a Technologie, 2024)
Na krátké ukázce z občanské války je vidět detailní popis umělou inteligencí toho, co se tam děje, ale je zajímavé, co nedokázala AI odhadnout, a to že vojáci pracovali s dělem a že stříleli na město.
Od metadat k přidané hodnotě a další možnosti AI
K čemu jsou všechny tyto nástroje včetně video popisu? Jejich výstupem jsou soubory dat, titulků, ruchů, zobrazených osob, které je možné agregovat do metadatových souborů doprovázejících jednotlivá videa následně pomocí nich vyhledávat určité, třeba zpravodajské spoty. A nejenom to, neuronové sítě dokážou vyhledávat sémanticky nebo významově bez fulltextového vyhledávání. Použití je možné pak pro vyhledání například zajímavých momentů ze sportovních přenosů.

Přehled možností využití video metadat (Zdroj: prezentace R.Mitka, konference Media a Technologie, 2024)
Dnes, kdy televizní společnosti využívají i internet, zejména ve zpravodajství, tak se hodí vytvářet zpravodajské články z obsahu reportáží, čemuž se použije sítě Whisper v kombinaci s Lama3.
Představte si, že máte interview nebo reportáž v televizním zpravodajství a chcete z toho rychle vygenerovat článek takový, který by vám sestavil nějaký redaktor, tak k tomu se dá použít nástroj na titulky a zároveň nějaký velký jazykový model, třeba ChatGPT, anebo pokud se bojíte o svoje data, tak právě zmíněnou Llamu. Výsledkem bude článek, který má nadpis a perex, má tělo a zároveň vystihuje ten popis toho rozhovoru včetně přímé řeči. Samozřejmě je nutno zkontrolovat a ověřit si, že to je správně.
A ještě poznámka na závěr
Tím, že jsme publikovali v přepisu (avšak nevytvořeném AI, ale autorem) tuto výjimečně kvalitní přednášku z konference Media a technologie, jsme snad vzbudili u čtenářů zájem o tuto rozvíjející technologii umělé inteligence.
AI je na pomezí žurnalistiky, medií a vysílání. Musíme si hrát s touto novou technologií, to je klíčové poselství, musíme si s ní hrát, když si s ní nehrajete, a plně nebude využívat, nebudete jí rozumět, kde jsou hranice jejích možností.
Jak jsme uvedli, některé aplikace lze využít z volně přístupných nástrojů na internetu a nainstalovat si je pro vlastní použití. Dejte nám vědět, zda vás článek zaujal a zda byste chtěli, abychom se touto tématikou dále zabývali.
Úvodní foto: simplylearn.com
